import pandas as pdمكتبة بانداس : الجزء 2

مقدمة
شاهد المقالة السابقة لمعرفة أهمية المكتبة وطريقة إستخدامها قبل رؤية هذه المقالة
تضمين المكتبة
نلاحظ هنا أنه يجب علينا الإلتزام بالاسم الذي أطلقناه على المكتبة وهو :
pd
وهذا الكلام عام على أي مكتبة في بايثون
الأوامر الأساسية
pd.read_csv('data/data.csv')
أمر قراءة ملف ذو صيغة :
CSV
pd.read_excel('data/data.xlsx')
أمر قراءة ملف مايكروسوفت إكسل
اقرأ هنا مايكروسوفت إكسل لتحليل البيانات
df = pd.read.csv('data.csv')
وضع ملف نصي داخل متغير
ويمكن الرؤية والقراءة من الملف بالأوامر التالية :
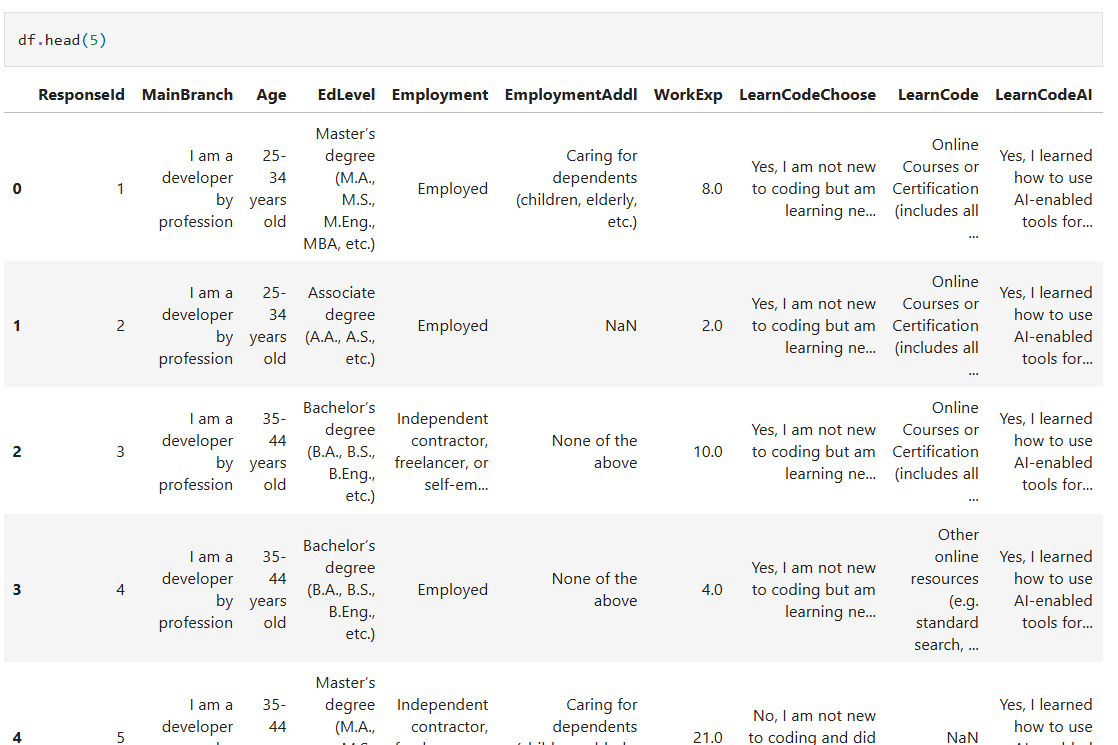
df.head()
حيث يظهر هذا الأمر الصفوف الأولية من البيانات
ويمكن إضافة رقم بين القوسين بهذا الشكل :
df.head(5) حيث يظهر بالضبط الصفوف الأولية الخمسة
وكذلك النقيض تماماً هو الأمر التالي :
df.tail()
وهو يظهر الصفوف الأخيرة في البيانات
يمكن كذلك في بانداس تحديد الصفوف والأعمدة المطلوبة لتجهيزها في عملية تعلم الآلة
مثلاً :
ages = df['Age'].value_counts() حيث حفظنا عمود الأعمار في بيانات موجودة عندنا محفوظة في بانداس مسبقاً وحفظناها في هذا المتغير , ويسهل علينا لاحقاً تدريب النموذج عليها .
بل ويمكن أيضاً تنظيف البيانات وإزالة الأعمدة غير الضرورية بأمر : dropna()
مع ضرورة تحديد المتطلبات بين القوسين كالآتي :
ages.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
الخلاصة
تعلمنا في هذه المقالة الأوامر الأساسية لمكتبة بانداس الخاصة بمعالجة البيانات تحديداً وتجهيزها لعملية تعلم الآلة وتدريب النموذج .
مصادر ومراجع :
- Pandas - Official site
- بانداس - ويكيبيديا
- Data Science Programming Book - For Dummies